Pasteurella multocida is a Gram-negative, non-motile coccobacillus in the family Pasteurellaceae, commonly found in the upper respiratory tract of many domestic and wild animals. It is clinically significant as the primary cause of soft-tissue infections following animal bites and scratches, and is also responsible for fowl cholera, haemorrhagic septicaemia in cattle, and atrophic rhinitis in swine. P. multocida displays considerable capsular diversity across five serogroups (A, B, D, E, F), with its genome encoding a range of virulence-associated factors including toxins, adhesins, and iron-acquisition systems.
Derived from 1,262 genomes: 208 from RefSeq and 1,054 from other sources. For the derivation pipeline and the PASS / WARN / FAIL verdict model, see the methods page for qualibact-v1.0.
Applied to the full All-The-Bacteria dataset, these thresholds place 971 genomes at PASS, 122 at WARN, and 46 at FAIL (1,139 assessed in total). The per-tier genome lists can be downloaded below in .csv.gz format; the FAIL list also records the reason each assembly was rejected.
This table summarises the distribution of each metric, including standard deviation, mean, median, and percentiles.
A combined summary table across all species is available on the summary page.
| Metric | Distribution | n | Mean | SD | Min | Q1 | Median | Q3 | Max |
|---|---|---|---|---|---|---|---|---|---|
| N50 | non-normal | 1,054 | 251,065 | 150,497 | 20,594 | 126,160 | 218,951 | 353,358 | 615,620 |
| no_of_contigs | non-normal | 1,054 | 46.33 | 29.31 | 14 | 27 | 36 | 57 | 198 |
| longest | non-normal | 1,054 | 450,762 | 168,343 | 76,685 | 327,573 | 525,470 | 596,808 | 792,317 |
| GC_Content | non-normal | 1,054 | 40.31 | 0.08 | 40.12 | 40.26 | 40.31 | 40.35 | 40.65 |
| Completeness_Specific | non-normal | 1,054 | 100 | 0 | 100 | 100 | 100 | 100 | 100 |
| Contamination | non-normal | 1,054 | 0.16 | 0.04 | 0.05 | 0.14 | 0.16 | 0.18 | 0.43 |
| Total_Coding_Sequences | non-normal | 1,054 | 2,141 | 86.07 | 2,011 | 2,079 | 2,119 | 2,183 | 2,469 |
| Genome_Size | non-normal | 1,054 | 2,295,005 | 59,795 | 2,187,095 | 2,254,207 | 2,282,217 | 2,322,781 | 2,528,949 |
Full statistics including KS test vs RefSeq and Wasserstein distance are in the downloadable summary.csv.
Derived from 1,262 genomes including 208 RefSeq references
Both Fail and Warn bands shown as the published rounded values — easier to cite and consistent across the species page, CSV downloads, and downstream QC tools.
| Metric | Fail below | Warn below | Warn above | Fail above |
|---|---|---|---|---|
| Genome_Size | 2,100,000 | 2,200,000 | 2,500,000 | 2,800,000 |
| GC_Content | 40 | 40.1 | 40.5 | 40.9 |
| Total_Coding_Sequences | 2,000 | 2,000 | 2,400 | 2,900 |
| Completeness_Specific | 90 | 100 | - | - |
| Contamination | - | - | 1 | 3 |
| N50 | 26,000 | 38,000 | - | - |
| no_of_contigs | - | - | 130 | 180 |
| longest | - | - | - | - |
How to read this: a value between the two warn columns is typical for this species and passes QC. A value between a warn column and the corresponding fail column is borderline — worth a manual look but not an outright failure. A value outside the fail columns is unusual enough to fail QC.
The published rounded thresholds (the values in the table above) were applied to the full AllTheBacteria-2024-08 set for this species. Each row carries the per-metric verdict and, where applicable, the reason a genome was demoted to WARN or FAIL. Files are gzipped CSV.
This plot shows the relationship between the number of coding sequences (CDS) and genome size — how the number of genes scales with assembly length. The relationship should be roughly linear: as genome size increases, the number of coding sequences should rise proportionally. A secondary trend line or non-linear behaviour can indicate either bona fide sub-populations within the retained genomes (e.g. distinct sub-clades) or residual contamination that survived filtering.
Histogram comparing SRA to RefSeq; each bar shows genome density across value ranges to highlight shifts, peaks, or outliers.
QQ (quantile-quantile) plot comparing SRA and RefSeq. Points along the diagonal follow the expected distribution; deviations indicate skew, outliers, or other systematic differences.
A table of complete RefSeq genomes for Pasteurella multocida used to calibrate this scheme. The file includes accessions, some sample information, genome size, GC content, and other key metrics.
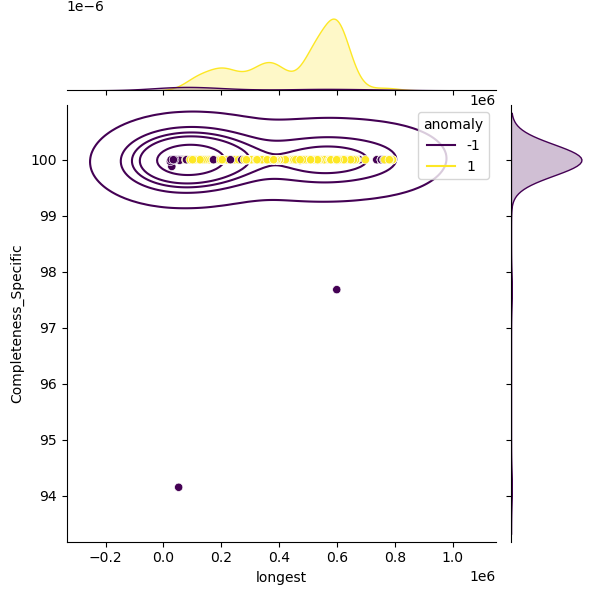
These plots show genomes before and after filtering to highlight the outliers removed:
The filtered distribution shown here may not exactly match the published thresholds because additional rounding and curator adjustments are applied on top.
{kind=link}
{kind=link}
{kind=link}