Mycobacterium kansasii is a slow-growing, photochromogenic, acid-fast bacillus in the family Mycobacteriaceae, and the non-tuberculous mycobacterium whose pulmonary disease most closely mimics tuberculosis both clinically and radiographically. It is predominantly acquired from municipal water supplies rather than soil, and infection is most common in individuals with underlying lung disease or immunosuppression, including HIV. The genome of M. kansasii (~6.4 Mb) is divided into distinct subtypes (I-VII), with subtype I responsible for the vast majority of human disease, and shares more genomic similarity with the M. tuberculosis complex than most other NTM.
For detailed methods on how these thresholds were calculated, please see Methods. The suggested thresholds are in the table below. These thresholds are based on 3 genomes from RefSeq and 724 genomes from other sources. These thresholds were applied to all the bacteria dataset, which resulted in removing 45 and retaining 682. The list of genomes retained (i.e. high quality) and the list of genomes rejected (filtered) can be downloaded below. These files are in .xz format. The rejected genomes file also includes the reason why.
These tables provide a summary of the distribution of each metric, including SDeviation, Mean, Median, and Percentiles.
These thresholds were applied to all the bacteria dataset. The list of genomes retained (i.e. high quality) and the list of genomes rejected (filtered) can be downloaded below. These files are in .xz format. The rejected genomes file also includes the reason why.
| Metric | Lower bound | Upper bound |
|---|---|---|
| N50 | 29,000 | - |
| no_of_contigs | - | 490.0 |
| GC_Content | 65.00 | 67.00 |
| Completeness | 99.00 | - |
| Contamination | - | 2.000 |
| Total_Coding_Sequences | 5,600 | 6,300 |
| Genome_Size | 6,300,000 | 6,900,000 |
This plot shows the relationship between the number of coding sequences (CDS) and genome size. It helps to visualize how genome size correlates with the number of genes. This should be linear – as genome size increases, the number of coding sequences should also increase. Any secondary trend lines or non-linear behaviour indicates bona fide separate populations within the retained genomes or some remaining contaminant.
Histogram comparing SRA to RefSeq; each bar shows genome density across value ranges to highlight shifts, peaks, or outliers.
QQ (quantile-quantile) plot comparing SRA and RefSeq. Points along the diagonal follow the expected distribution; deviations indicate skew, outliers, or other systematic differences.
A table of complete RefSeq genomes for Mycobacterium kansasii used to calibrate this scheme. The file includes accessions, some sample information, genome size, GC content, and other key metrics.
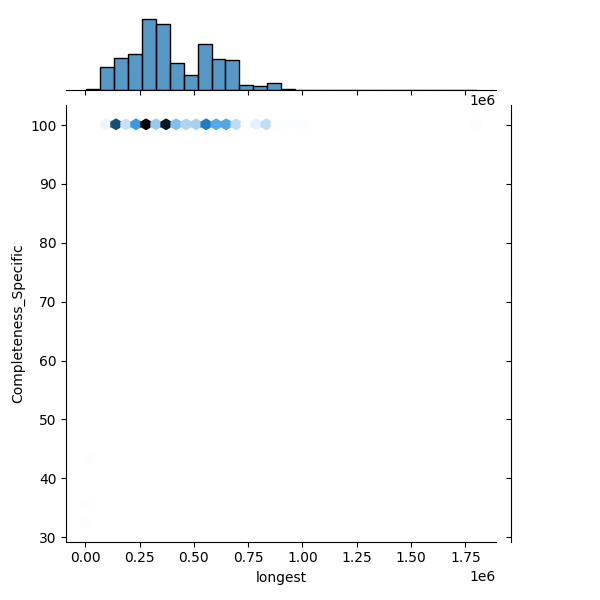
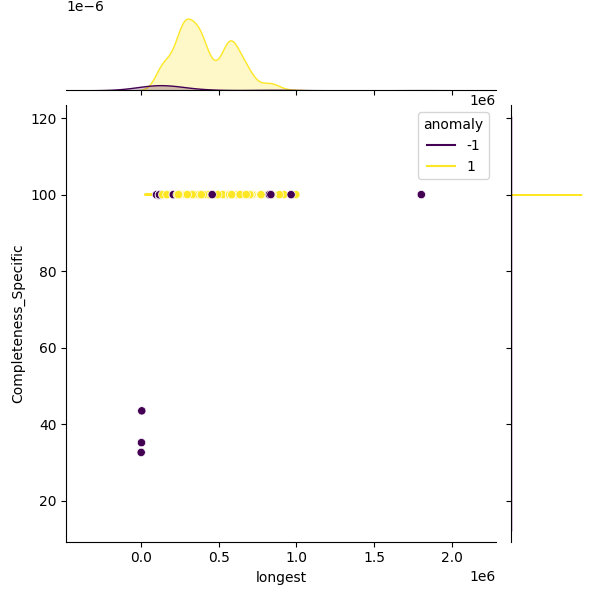
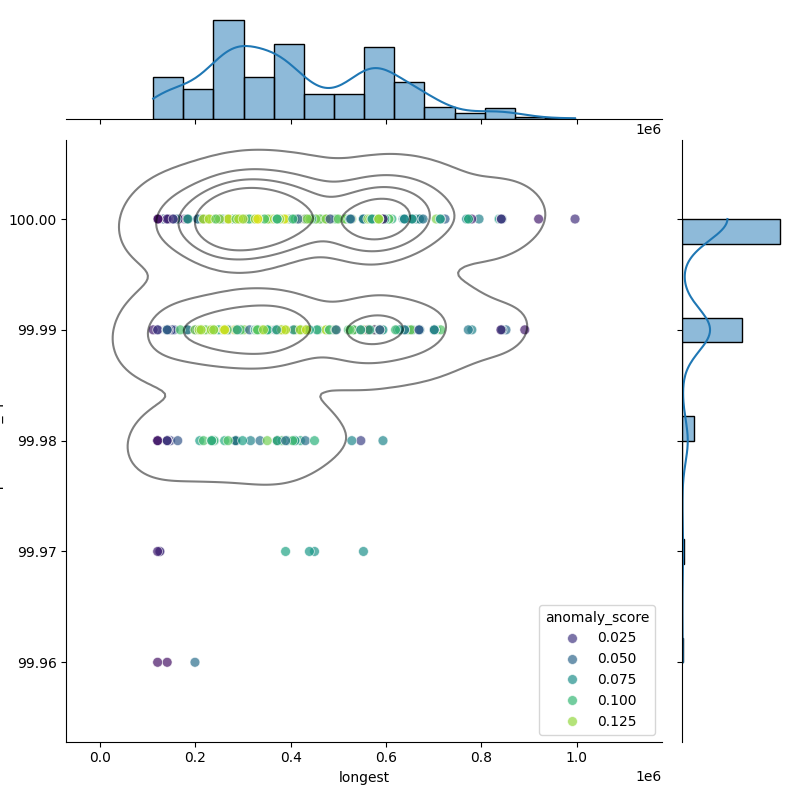
These plots show genomes before and after filtering to highlight the outliers removed. Left: Heatmap of all genomes in the dataset. Middle: A representative sample of genomes, with anomalies highlighted (purple). Right: The filtered distribution after applying filtering. There may have been additional adjustments and rounding so the distribution here may not enirely match with the final suggested metrics.
{kind=link}
{kind=link}
{kind=link}