Klebsiella quasipneumoniae is a Gram-negative, facultatively anaerobic, encapsulated rod in the family Enterobacteriaceae, closely related to Klebsiella pneumoniae and separated from it through genomic analyses. It comprises two subspecies (subsp. quasipneumoniae and subsp. similipneumoniae) and is isolated from clinical specimens including blood, urine, and respiratory samples. K. quasipneumoniae can harbour extended-spectrum beta-lactamase and carbapenemase genes, though it is generally less frequently associated with multidrug resistance and hypervirulence than K. pneumoniae.
Derived from 2,156 genomes: 176 from RefSeq and 1,980 from other sources. For the derivation pipeline and the PASS / WARN / FAIL verdict model, see the methods page for qualibact-v1.1.
Applied to the full All-The-Bacteria dataset, these thresholds place 1,790 genomes at PASS, 228 at WARN, and 74 at FAIL (2,092 assessed in total). The per-tier genome lists can be downloaded below in .csv.gz format; the FAIL list also records the reason each assembly was rejected.
This table summarises the distribution of each metric, including standard deviation, mean, median, and percentiles.
A combined summary table across all species is available on the summary page.
| Metric | Distribution | n | Mean | SD | Min | Q1 | Median | Q3 | Max |
|---|---|---|---|---|---|---|---|---|---|
| N50 | non-normal | 1,980 | 336,753 | 204,371 | 24,129 | 198,894 | 305,686 | 399,733 | 1,472,835 |
| no_of_contigs | non-normal | 1,980 | 82.92 | 57.25 | 16 | 46 | 69 | 102 | 505 |
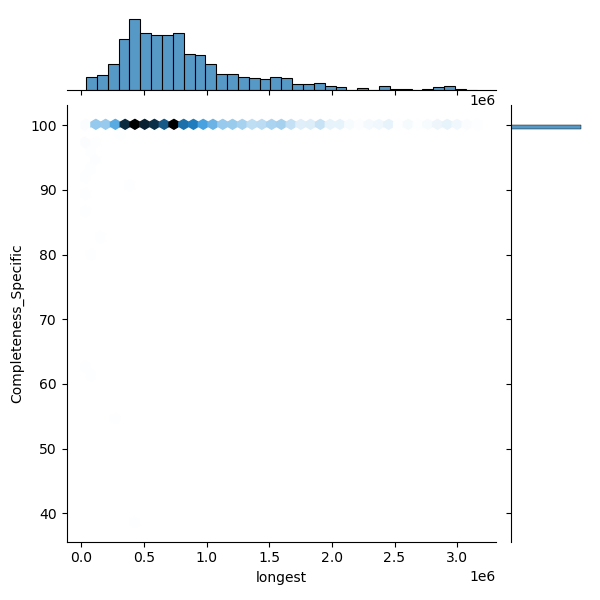
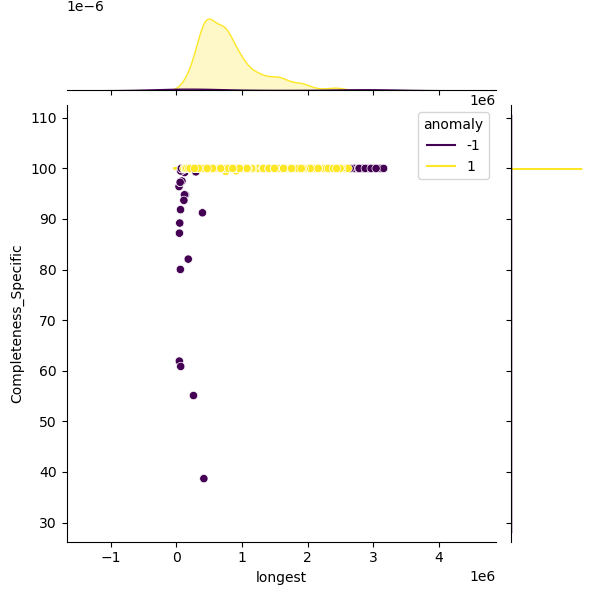
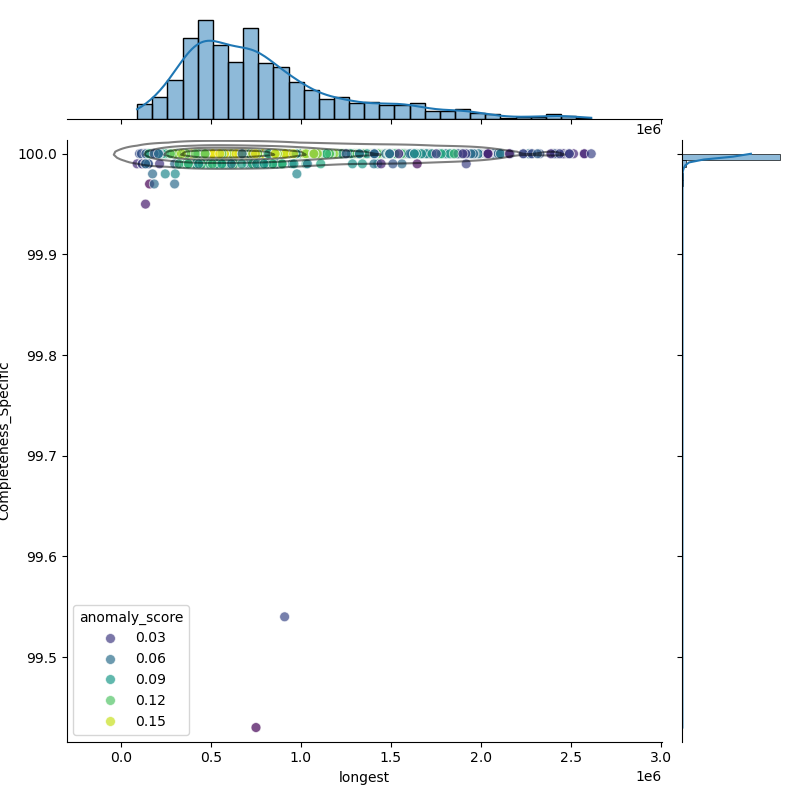
| longest | non-normal | 1,980 | 802,882 | 463,295 | 89,734 | 465,493 | 702,615 | 996,684 | 2,613,339 |
| GC_Content | non-normal | 1,980 | 57.7 | 0.32 | 56.59 | 57.5 | 57.73 | 57.91 | 58.43 |
| Completeness_Specific | non-normal | 1,980 | 100 | 0.02 | 99.43 | 100 | 100 | 100 | 100 |
| Contamination | non-normal | 1,980 | 0.22 | 0.29 | 0 | 0.04 | 0.11 | 0.31 | 3.72 |
| Total_Coding_Sequences | non-normal | 1,980 | 5,142 | 258.58 | 4,610 | 4,947 | 5,132 | 5,308 | 5,953 |
| Genome_Size | non-normal | 1,980 | 5,472,395 | 221,270 | 4,974,325 | 5,309,497 | 5,457,050 | 5,603,864 | 6,208,270 |
Full statistics including KS test vs RefSeq and Wasserstein distance are in the downloadable summary.csv.
Derived from 2,156 genomes including 176 RefSeq references
Both Fail and Warn bands shown as the published rounded values — easier to cite and consistent across the species page, CSV downloads, and downstream QC tools.
| Metric | Fail below | Warn below | Warn above | Fail above |
|---|---|---|---|---|
| Genome_Size | 4,500,000 | 5,000,000 | 6,000,000 | 6,300,000 |
| GC_Content | 56.4 | 56.9 | 58.3 | 58.7 |
| Total_Coding_Sequences | 4,400 | 4,700 | 5,700 | 6,300 |
| Completeness_Specific | 97 | 99 | - | - |
| Contamination | - | - | 1 | 3 |
| N50 | 33,000 | 60,000 | - | - |
| no_of_contigs | - | - | 230 | 390 |
| longest | - | - | - | - |
How to read this: a value between the two warn columns is typical for this species and passes QC. A value between a warn column and the corresponding fail column is borderline — worth a manual look but not an outright failure. A value outside the fail columns is unusual enough to fail QC.
The published rounded thresholds (the values in the table above) were applied to the full AllTheBacteria-2024-08 set for this species. Each row carries the per-metric verdict and, where applicable, the reason a genome was demoted to WARN or FAIL. Files are gzipped CSV.
This plot shows the relationship between the number of coding sequences (CDS) and genome size — how the number of genes scales with assembly length. The relationship should be roughly linear: as genome size increases, the number of coding sequences should rise proportionally. A secondary trend line or non-linear behaviour can indicate either bona fide sub-populations within the retained genomes (e.g. distinct sub-clades) or residual contamination that survived filtering.
Histogram comparing SRA to RefSeq; each bar shows genome density across value ranges to highlight shifts, peaks, or outliers.
QQ (quantile-quantile) plot comparing SRA and RefSeq. Points along the diagonal follow the expected distribution; deviations indicate skew, outliers, or other systematic differences.
A table of complete RefSeq genomes for Klebsiella quasipneumoniae used to calibrate this scheme. The file includes accessions, some sample information, genome size, GC content, and other key metrics.
Per-assembly inputs the engine used to derive the Klebsiella quasipneumoniae reference distribution for this scheme: sample, sylph species call, N50, contig count, longest contig, total length, completeness, contamination, total coding sequences, genome size, GC content. Gzipped CSV.
These plots show genomes before and after filtering to highlight the outliers removed:
The filtered distribution shown here may not exactly match the published thresholds because additional rounding and curator adjustments are applied on top.
{kind=link}
{kind=link}
{kind=link}